
Актуальность исследования
В условиях роста объемов данных и увеличения потребности в быстром извлечении аналитической информации оптимизация запросов к базам данных становится одной из ключевых задач для обеспечения высокой производительности современных информационных систем. Эффективная обработка запросов играет критическую роль в бизнес-аналитике, принятии управленческих решений и построении прогнозных моделей.
Сложность выполнения запросов возрастает из-за увеличения объема хранимых данных, сложности их структур, а также применения распределенных систем хранения. Это делает традиционные подходы менее эффективными и требует внедрения новых методов оптимизации. Актуальность темы также обусловлена развитием технологий обработки больших данных, распределенных систем и искусственного интеллекта, которые открывают новые возможности для улучшения производительности аналитических процессов.
Цель исследования
Целью данного исследования является анализ и систематизация методов оптимизации запросов к базам данных, направленных на повышение производительности аналитических систем, а также выявление наиболее эффективных подходов и технологий, применимых в различных условиях.
Материалы и методы исследования
Исследование основано на анализе научной литературы, а также на результатах практических экспериментов с использованием реляционных (PostgreSQL, MySQL) и NoSQL баз данных (MongoDB, Cassandra).
Для анализа производительности использовались методы профилирования запросов, а также тестирование до и после оптимизации с использованием инструментов мониторинга и анализа времени выполнения запросов. В рамках кейс-стади были рассмотрены примеры оптимизации в промышленной среде. Оценка эффективности проводилась с помощью сравнения времени выполнения запросов до и после применения оптимизационных техник.
Результаты исследования
Системы управления базами данных (СУБД) являются основными инструментами для хранения, управления и извлечения данных в различных информационных системах. Их производительность напрямую влияет на эффективность обработки информации и, следовательно, на общую производительность приложений, использующих эти системы.
СУБД обеспечивают взаимодействие между пользователями и базами данных, предоставляя средства для определения, создания, модификации и управления данными. Основные компоненты СУБД включают:
- Ядро СУБД отвечает за выполнение основных операций по хранению и извлечению данных, управление транзакциями и поддержание целостности данных.
- Процессор запросов обрабатывает запросы пользователей, выполняя синтаксический и семантический анализ, оптимизацию и генерацию плана выполнения запроса.
- Система управления буферами обеспечивает кэширование данных в оперативной памяти для ускорения доступа и уменьшения количества операций ввода-вывода.
Производительность СУБД зависит от эффективности работы этих компонентов. Например, оптимизация работы процессора запросов может значительно сократить время выполнения сложных запросов, а эффективное управление буферами снижает задержки при доступе к данным [2, с. 25].
Обработка запроса в СУБД проходит через несколько ключевых этапов:
- Синтаксический анализ. На этом этапе СУБД проверяет корректность синтаксиса запроса и строит его внутреннее представление в виде дерева разбора.
- Семантический анализ. Проверяется соответствие запроса структуре базы данных, включая существование упомянутых таблиц и столбцов, а также соответствие типов данных.
- Оптимизация запроса. СУБД анализирует возможные планы выполнения запроса и выбирает наиболее эффективный с точки зрения использования ресурсов. Это может включать выбор оптимальных методов соединения таблиц, использование индексов и определение порядка выполнения операций [4, с. 6].
- Генерация плана выполнения. На основе оптимизированного плана создается последовательность операций, которые будут выполнены для получения результата запроса.
- Выполнение запроса. СУБД выполняет сгенерированный план, взаимодействуя с хранилищем данных и возвращая результат пользователю.
Каждый из этих этапов влияет на общее время выполнения запроса и потребление ресурсов системы. Особенно критичен этап оптимизации, так как от выбора плана выполнения зависит эффективность использования ресурсов СУБД.
Таблица 1 отражает основные аспекты, которые следует учитывать для достижения оптимальной производительности запросов.
Таблица 1
Факторы, влияющие на производительность запросов в СУБД
Фактор | Описание | Влияние на производительность |
Структура базы данных | Проектирование схемы базы данных (нормализация, денормализация) | Неправильная структура увеличивает количество операций соединения и поиска |
Индексация | Использование кластерных, некластерных, полнотекстовых индексов | Ускоряет поиск данных, но увеличивает время операций вставки и обновления |
Объем данных | Объем хранимой информации и её распределение по таблицам и разделам | Большой объем данных может приводить к увеличению времени выборки, если не применяются индексы или партиционирование |
Аппаратные ресурсы | Производительность процессора, объем оперативной памяти, скорость дисков и сети | Недостаток ресурсов увеличивает время выполнения запросов, особенно при интенсивной нагрузке |
Конкурентный доступ | Одновременный доступ множества пользователей или процессов | Может приводить к блокировкам и снижению скорости выполнения запросов |
Конфигурация СУБД | Настройки памяти, параметров кэширования, параллелизма, размеров буферов | Неправильные настройки снижают эффективность использования ресурсов |
Оптимизация запросов является ключевым аспектом обеспечения высокой производительности систем управления базами данных. Современные подходы к оптимизации затрагивают как уровни проектирования базы данных, так и оптимизацию самих запросов, включая использование современных инструментов и технологий. Рассмотрим основные методы оптимизации запросов:
1. Оптимизация на уровне проектирования базы данных:
1) Нормализация и денормализация
Нормализация – это процесс приведения структуры базы данных к форме, минимизирующей избыточность данных и обеспечивающей целостность. Этот процесс важен для снижения объема хранения и упрощения обновления данных. Однако чрезмерная нормализация может привести к увеличению количества операций соединения (JOIN) и, как следствие, к снижению производительности запросов.
Денормализация, напротив, позволяет сократить число JOIN-операций за счет объединения данных в одну таблицу. Это может быть полезно для аналитических задач, требующих высокой скорости выборки, особенно в колоночных базах данных, таких как ClickHouse.
2) Индексация
Индексы ускоряют операции выборки за счет упорядочивания данных и упрощения поиска [1, с. 9]. Эффективная индексация может включать:
- Кластерные индексы организуют физический порядок данных в таблице в соответствии с индексируемыми столбцами.
- Некластерные индексы создают отдельные структуры для ускорения поиска.
- Полнотекстовые индексы используются для поиска по текстовым данным.
Рисунок 1 демонстрирует сокращение времени выборки с использованием индекса.
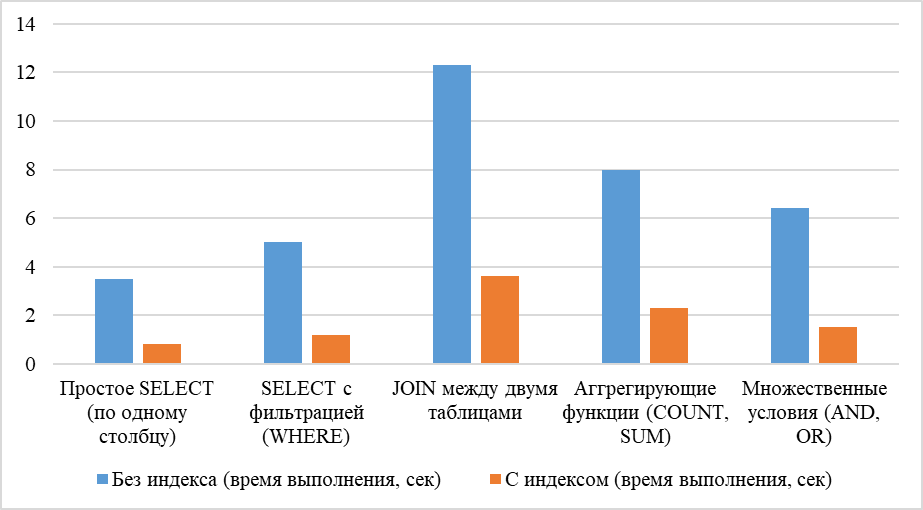
Рис. 1. Влияние индексов на производительность запросов
2. Оптимизация запросов:
1) Упрощение SQL-запросов
Комплексные запросы с большим числом подзапросов, операций группировки и фильтрации требуют значительных вычислительных ресурсов.
Упрощение запросов может включать:
- Разделение сложных запросов на несколько простых.
- Использование временных таблиц для хранения промежуточных результатов.
- Сведение количества подзапросов к минимуму.
2) Использование хранимых процедур и представлений
Хранимые процедуры и представления позволяют заранее определить и оптимизировать выполнение стандартных запросов. Представления уменьшают сложность запросов на стороне клиента, а хранимые процедуры позволяют передавать предварительно оптимизированный код на выполнение в СУБД.
3. Использование инструментов и технологий:
1) Анализ и профилирование запросов
Современные СУБД предоставляют встроенные инструменты для анализа выполнения запросов, такие как EXPLAIN (в PostgreSQL) или Query Analyzer (в Microsoft SQL Server) (табл. 2). Эти инструменты помогают выявить «узкие места», такие как операции полного сканирования таблиц или неоптимальное использование индексов.
Таблица 2
Влияние различных инструментов профилирования на производительность запросов
Инструмент | Функциональность | Эффект |
EXPLAIN (PostgreSQL) | Показывает план выполнения запроса | Выявляет проблемы индексации |
Query Analyzer | Анализирует запросы и их производительность | Оптимизирует работу планировщика |
Performance Insights | Оценивает производительность Amazon Aurora | Уменьшает задержки запросов |
2) Кэширование
Кэширование позволяет сократить повторные обращения к базе данных за счет хранения результатов запросов в оперативной памяти. Эффективное кэширование может быть реализовано на уровне СУБД (например, MySQL Query Cache) или на уровне приложения (например, Memcached, Redis).
3) Использование современных технологий
- Колоночные базы данных (ClickHouse, оптимизированные для аналитических запросов).
- Распределенные системы (Apache Hadoop или Spark, которые позволяют параллельно обрабатывать большие объемы данных).
Кейсы успешной оптимизации запросов:
Пример 1: Оптимизация реляционной базы данных
Для реляционных баз данных, таких как PostgreSQL или MySQL, основными методами оптимизации являются нормализация, денормализация, индексация и использование кэширования. Например, в одном из проектов на базе PostgreSQL была оптимизирована структура таблиц и добавлены индексы по наиболее часто используемым столбцам, что позволило уменьшить время выполнения сложных запросов с несколькими соединениями. Результатом стало сокращение времени выполнения отчетных запросов с 15 секунд до 3 секунд, что значительно повысило производительность приложения и улучшило пользовательский опыт [3, с. 54].
Кроме того, в рамках этого проекта была использована денормализация некоторых данных для ускорения выборки, что позволило избавиться от необходимости многократных JOIN-операций.
Пример 2: Применение NoSQL и распределенных систем
В проектах, где используется NoSQL-база данных, например, MongoDB или Cassandra, основное внимание уделяется масштабируемости и производительности при работе с большими объемами данных. Для анализа больших потоков данных и высоконагруженных систем часто используют распределенные базы данных, такие как Apache HBase или Couchbase. Примером может служить проект с использованием MongoDB, где были оптимизированы запросы за счет использования агрегации и предобработки данных в фоне, что позволило улучшить скорость выборки данных в 5 раз.
Кроме того, для распределенных систем ключевым элементом является использование репликации и шардирования данных, что обеспечивает балансировку нагрузки и отказоустойчивость. Например, в проекте с Cassandra применение шардирования позволило распределить запросы между несколькими узлами, что обеспечило значительное улучшение производительности при работе с миллиардами записей [5, с. 62].
Рисунок 2 иллюстрирует улучшение времени выполнения запросов при использовании шардирования и репликации в распределенных системах.
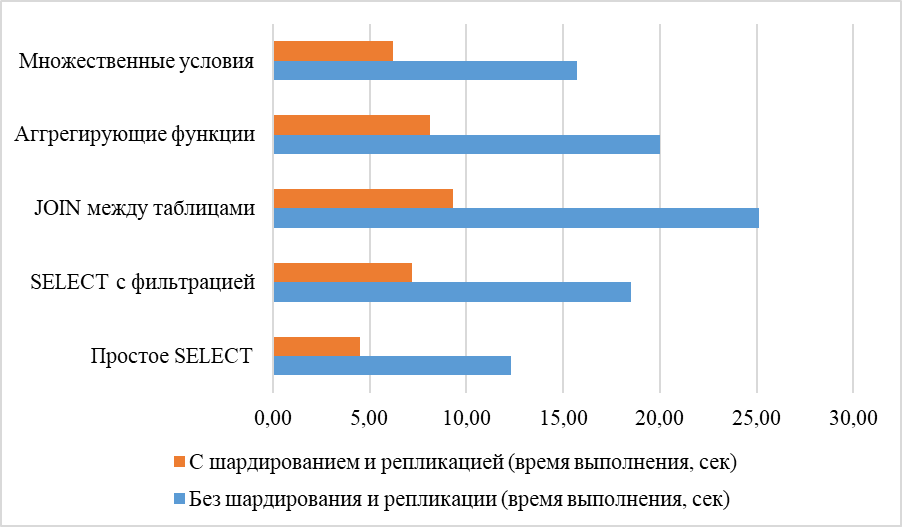
Рис. 2. Влияние шардирования и репликации на производительность запросов
Несмотря на значительные преимущества методов оптимизации запросов, существует ряд ограничений и сложностей, которые необходимо учитывать при их применении:
- Усложнение структуры данных. Применение денормализации, хотя и увеличивает скорость выборки, может привести к проблемам с консистентностью данных, поскольку обновления должны выполняться в нескольких местах.
- Затраты на индексацию. Несмотря на то, что индексы значительно ускоряют выполнение запросов, они также занимают дополнительное место в базе данных и могут замедлить операции вставки и обновления. Определение нужных индексов для разных типов запросов является задачей, требующей тонкой настройки.
- Избыточное кэширование. Кэширование ускоряет повторные запросы, однако оно может привести к проблемам с устареванием данных, если кэш не обновляется корректно. В случае изменения данных в базе нужно тщательно контролировать актуальность данных в кэше.
- Ограничения распределенных систем. Использование распределенных систем, таких как Apache Hadoop или Cassandra, требует наличия соответствующей инфраструктуры и управления. Эти системы могут быть сложными для настройки и требуют значительных вычислительных ресурсов для масштабирования.
- Управление конкурентным доступом. В многопользовательских системах могут возникать проблемы с блокировками и конкуренцией за ресурсы. Методы оптимизации, такие как использование оптимистичных и пессимистичных блокировок, должны быть тщательно настроены для предотвращения деградации производительности.
Каждый метод оптимизации имеет свои ограничения, и для его успешного применения необходимо учитывать специфику проекта и требуемую нагрузку на систему.
С развитием технологий появляются новые методы и подходы к оптимизации запросов, которые способствуют улучшению производительности и эффективности работы с базами данных. Некоторые из перспективных направлений включают:
- Использование искусственного интеллекта и машинного обучения. Современные алгоритмы ИИ могут автоматически анализировать и оптимизировать запросы, предсказывая наиболее эффективные пути выполнения на основе исторических данных о запросах и производительности.
- Гибридные базы данных. Комбинирование реляционных и NoSQL решений (например, гибридные СУБД), что позволяет использовать сильные стороны обеих архитектур в одном решении для разных типов данных и запросов.
- Автоматическая оптимизация на уровне СУБД. Современные СУБД начинают внедрять методы автоматического анализа и оптимизации запросов без вмешательства пользователя. Это включает динамическую настройку индексов, автоматическое распараллеливание запросов и более гибкое управление памятью.
- Использование колоночных баз данных. Для аналитических задач продолжается активное развитие колоночных баз данных, таких как ClickHouse и Apache HBase, которые значительно ускоряют обработку запросов на больших объемах данных.
- Квантовые вычисления. В долгосрочной перспективе квантовые вычисления могут оказать влияние на методы обработки и оптимизации запросов в базе данных, открывая новые возможности для параллельных вычислений и обработки сложных данных.
Эти подходы обещают значительные улучшения в производительности запросов и более гибкие решения для работы с большими объемами данных.
Выводы
Таким образом, применение методов оптимизации запросов, таких как индексация, шардирование и репликация, значительно ускоряет обработку данных и повышает производительность систем. Использование машинного обучения и искусственного интеллекта для автоматической оптимизации запросов открывает новые возможности для повышения эффективности работы с базами данных. Однако необходимо учитывать ограничения этих методов, такие как увеличение сложности настройки и потенциальные проблемы с консистентностью данных. Перспективные направления, такие как гибридные базы данных и использование квантовых вычислений, обещают дальнейшее улучшение производительности в будущем.
