
Актуальность исследования
Актуальность исследования определяется возрастающей ролью технологий искусственного интеллекта и аналитики больших данных в управлении финансовыми потоками технологических предприятий. Современные компании сталкиваются с увеличением объёмов и скорости обработки информации, что затрудняет своевременное выявление скрытых ошибок, мошеннических действий или нетипичных транзакций.
Традиционные методы аудита и бухгалтерского контроля часто оказываются недостаточно оперативными и не способны работать в режиме реального времени, что повышает риск накопления критических аномалий и финансовых потерь. В условиях высокой конкуренции и нестабильной экономической среды именно способность к раннему обнаружению финансовых отклонений становится стратегическим фактором обеспечения устойчивости бизнеса.
Для технологических предприятий, где характерны значительные вложения в исследования и разработки, нестабильность денежных потоков и активное использование венчурных и инновационных инструментов финансирования, наличие адаптивных алгоритмов мониторинга является ключевым условием безопасности и надежности функционирования.
Применение алгоритмов машинного обучения и автоматизированных систем анализа позволяет значительно повысить эффективность контроля и снизить вероятность человеческих ошибок, однако требует научного обоснования, адаптации к специфике бизнеса и устранения рисков ложных срабатываний.
Цель исследования
Цель исследования заключается в разработке и обосновании алгоритма отслеживания и раннего выявления финансовых аномалий в технологических предприятиях. Предполагается, что разработанный подход позволит своевременно выявлять риски и предотвращать убытки, адаптируясь к специфике технологических организаций, их финансовых процессов и структуры денежных потоков.
Материалы и методы исследования
Материалы и методы исследования включали анализ открытых транзакционных наборов данных и профильных отраслевых отчётов, а также изучение технической документации по потоковой обработке и моделям обнаружения аномалий. Данные проходили предобработку (очистка, нормализация, отбор признаков), после чего применялись как несупервизированные алгоритмы для моделирования «нормального» поведения, так и супервизированные модели для сравнения подходов. Оценка качества выполнялась на отложенных выборках с использованием ROC-AUC и PR-AUC, а также анализа рабочих порогов. Архитектурно рассматривался потоковый конвейер онлайн-скоринга с последующим мониторингом дрейфа данных и проверкой интерпретируемости результатов.
Результаты исследования
Теоретические основы обнаружения финансовых аномалий опираются на междисциплинарный корпус работ по аудиту, прикладной статистике и машинному обучению. В финансовых потоках технологических компаний аномалии чаще всего ассоциируются с ошибками учёта, мошенничеством, сбоями интеграционных контуров и нетипичными транзакциями в высокочастотных и разнопрофильных системах (ERP, биллинг, платёжные шлюзы). Эмпирическая база отрасли подтверждает масштаб задачи: по данным ACFE в издании 2022 года исследовано 2 110 реальных случаев в 133 странах с совокупными потерями $3,6 млрд и типичной (медианной) потерей на кейс 117 тыс.; значимую роль в своевременном выявлении отклонений играют «tips» (сообщения) и внутренние контроли, что подталкивает компании к сочетанию автоматических детекторов с организационными механизмами сообщения о рисках [2].
Классификационно аномалии удобно группировать по источнику и механизму возникновения:
- Бухгалтерско-учётные ошибки и искажения первички,
- Мошеннические схемы (присвоение активов, коррупция, манипулирование отчётностью),
- Системные сбои (дубли, рассинхронизация справочников, неверные курсы/ставки из внешних провайдеров),
- Поведенческие нетипичности в платёжных и контрактных данных.
В практике аудита базовым «экспресс-тестом» остаётся проверка на соответствие распределению первых цифр по закону Бенфорда; ожидаемые частоты для первой цифры d вычисляются по формуле P(d)=log10(1+1/d), и заметные отклонения в агрегатах могут служить индикатором аномалий или, по крайней мере, триггером для последующего углублённого анализа. При этом применимость тестов Бенфорда зависит от природы данных (масштабируемые, неограниченные сверху положительные величины) и контекста формирования записей [7].
Ожидаемые частоты первой цифры по закону Бенфорда (десятичная система) представлены на рисунке 1.
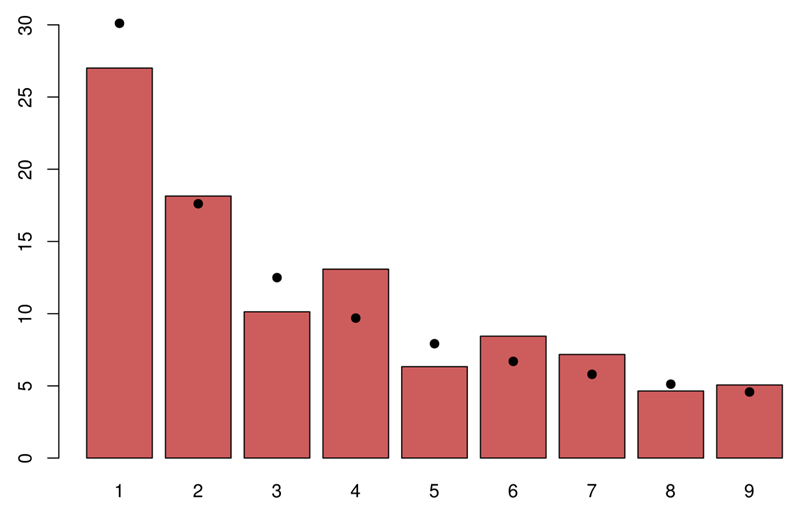
Рис. 1. Ожидаемые частоты первой цифры по закону Бенфорда (десятичная система) [4]
Машинное обучение расширяет арсенал за счёт супервизированных, полу- и не-супервизированных техник. В обзорах 2022 года показано, что в задачах финансового мошенничества применяются деревья решений и ансамбли, SVM, логистическая регрессия, вероятностные модели, а также глубокие автоэнкодеры и графовые подходы; при этом из-за сильного дисбаланса классов и эволюции паттернов предпочтение часто отдают не- и полу-супервизированным алгоритмам, способным моделировать «нормальное» поведение и выделять отклонения [6].
Ниже приведена сводная таблица методов (табл. 1), их природы и практических особенностей применения в финансовых данных (по систематическим обзорам и документации библиотек).
Таблица 1
Методы обнаружения финансовых аномалий
Метод/алгоритм | Тип подхода | Ключевая идея | Сильные стороны | Ограничения на финданных |
Закон Бенфорда | Статистический (правило распределений) | Логарифмическое распределение первых цифр сумм | Простота, быстрый скрининг больших реестров | Чувствителен к структуре данных, не «доказывает» мошенничество |
One-Class SVM | Не/полу-супервизированный | Оценка опоры распределения нормальных наблюдений | Работает при отсутствии меток «мошенничество» | Квадратичная масштабируемость, чувствительность к параметрам ядра |
Isolation Forest | Не/супервизированный (анализ путей в случайных деревьях) | Аномалии изолируются короче в случайных разбиениях | Эффективен на больших наборах, мало предположений о распределении | Может давать ложные срабатывания при кластерной структуре расходов |
Local Outlier Factor (LOF) | Наблюдательный, плотностный | Сравнение локальных плотностей соседей | Хорош для локальных «выбросов» в неоднородных данных | Нестабилен к выбору k и масштабу признаков |
Деревья/Ансамбли (RF, GBM) | Супервизированный | Обучение по размеченным кейсам мошенничества | Интерпретируемость признаков, высокая точность при метках | Требуются метки, риск переобучения при дисбалансе |
Автоэнкодеры (DL) | Не/полу-супервизированный (восстановление) | Реконструкция «нормы», высокий остаток = аномалия | Улавливают сложные нелинейности | Нужен объём «чистых» данных и контроль ложных срабатываний |
Сопоставление алгоритмов важно связывать с эмпирикой выявления. Согласно интерпретациям отчёта ACFE 2022, наиболее частые каналы детекции – «подсказки» (около 42%), затем внутренний аудит (~16%) и управленческий обзор (~12%). Это подтверждает, что алгоритмы должны не заменять, а усиливать контуры контроля: автоматизированный мониторинг транзакций сокращает длительность схем и медианный ущерб по сравнению с организациями без таких инструментов. Для технологических компаний, где высока сложность потоков и интенсивны операции между системами ERP/CRM/внешними платёжными сервисами, эффект особенно заметен [1].
Сравнительный обзор алгоритмов подтверждает: выбор метода зависит от наличия разметки, дисбаланса классов, требований к интерпретируемости и пропускной способности системы. Для внедрения на технологических предприятиях практичны смешанные конвейеры: инженерия признаков из бухгалтерских и платёжных событий, модель «нормы» на неразмеченных данных, поверх – детектор отклонений и приоритизация алертов, интегрированная с линиями внутреннего аудита и механизмами конфиденциальных сообщений.
Финансовые процессы технологических предприятий отличает высокая доля нематериальных активов, интенсивные и цикличные инвестиции в НИОКР и подписочные модели монетизации (SaaS), из-за чего выручка и денежные потоки часто расходятся по времени. Применение IFRS 15 для многокомпонентных договоров (лицензии, обновления, «stand-ready» услуги) и правил IAS 38 по капитализации этапа разработки формирует характерные «законные» сдвиги в учёте, которые нельзя путать с аномалиями.
Рыночная конъюнктура венчурного капитала усиливает волатильность: в фазах сжатия финансирования компании ускоренно пересматривают бюджеты, скорость горения и графики платежей, что меняет сезонность и амплитуду транзакций. В совокупности это требует от систем раннего обнаружения аномалий учитывать отраслевые особенности: различать кассовые и учетные эффекты, привязывать пороги тревог к фазам инвестиционного цикла и бюджетированию R&D, а также учитывать подписочные профили выручки и отложенные доходы. Такой контекстно-зависимый подход снижает долю ложных срабатываний при сохранении чувствительности к действительно нетипичным отклонениям.
Методология и архитектура предлагаемого алгоритма базируются на общепринятом конвейере «данные → обработка → модель → оценка → эксплуатация» и опираются на проверяемые практики промышленного антифрода. Для интеграции в ИТ-ландшафт технологического предприятия целесообразно использовать потоковую схему с приёмом событий из транзакционных систем, обогащением историческим контекстом и скорингом в реальном времени. В референс-архитектурах ведущих облачных платформ это реализуется через входной API-шлюз и поток (например, Amazon API Gateway/Kinesis), вызов обученных моделей (SageMaker) и запись результатов в хранилище, с возможностью параллельного аномального скоринга (Random Cut Forest) и супервизированной классификации (XGBoost) для принятия решений на основе правил и порогов.
На рисунке 2 показан потоковый конвейер для онлайн-скоринга транзакций: входящие события поступают через потоковую подсистему (Amazon Kinesis Data Firehose), обрабатываются AWS Lambda и направляются на два независимых ML-эндпойнта в Amazon SageMaker – для детекции аномалий (Random Cut Forest) и для детекции мошенничества (например, XGBoost).
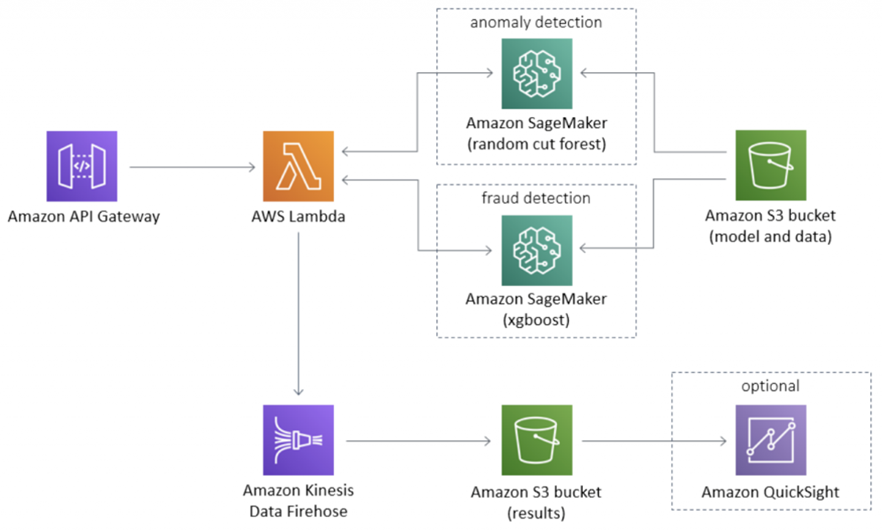
Рис. 2. Потоковая архитектура онлайн-скоринга транзакций на AWS: Kinesis → SageMaker (RCF, XGBoost) → S3/QuickSight [3]
Практическая апробация алгоритма целесообразна на открытом наборе транзакций по банковским картам, который широко используется в исследованиях и содержит метки мошенничества. Набор данных включает 284 807 транзакций за два дня, из них 492 случая мошенничества (≈0,172%), признаки анонимизированы (PCA-компоненты V1…V28) и дополнены полями Time и Amount. Это создаёт реалистичную среду для тестирования конвейеров детекции и оценки метрик устойчивости к дисбалансу. На базе этого датасета многочисленные публичные ноутбуки демонстрируют процедуры обучения и валидации моделей, что позволяет воспроизводимо сравнить результаты различных алгоритмов и настроек порогов [5].
Ниже приведена сводка базовых элементов типовой потоковой архитектуры для онлайн-скоринга финансовых транзакций в реальном времени (табл. 2).
Таблица 2
Компоненты референс-архитектуры для онлайн-скоринга
Компонент | Назначение |
API Gateway / AppSync | Приём событий и вызов скоринга |
Kinesis Data Firehose / MSK | Потоковая доставка/буфер |
SageMaker (Random Cut Forest, XGBoost) | Аномальный скоринг + классификация |
S3/Athena/QuickSight | Хранилище результатов и аналитика |
Neptune (граф) | Графовый контекст/поиск паттернов |
Дискуссия и ограничения исследования сводятся к трем группам вопросов. Во-первых, ограниченность и смещение открытых данных: популярный набор с банковскими картами отражает лишь двухдневный период, с сильным дисбалансом и PCA-трансформацией признаков, что ограничивает переносимость выводов на корпоративные финансы технологических компаний; вместе с тем он полезен для тестирования схем оценки и порогов. Во-вторых, чувствительность моделей к дрейфу данных и сезонности: исследования по dataset shift/ concept drift для антифрода показывают, что поведение покупателей и злоумышленников изменяется во времени, поэтому требуется регулярное обновление моделей и мониторинг дрейфа, иначе метрики деградируют. В-третьих, интерпретируемость и операционные риски: даже при высоком ROC-AUC избыток ложноположительных срабатываний перегружает линии разбора; потому в эксплуатации полезны объяснимость предсказаний, правила маршрутизации алертов и комбинирование каналов детекции с традиционными практиками контроля, подтверждёнными отраслевой статистикой.
Выводы
Исследование подтверждает уместность комбинированного подхода к раннему обнаружению финансовых аномалий в технологических предприятиях: статистический экспресс-скрининг, модель «нормы» для нетипичностей и супервизированная классификация для подтверждения сигналов в связке с бизнес-правилами и организационными контролями. Применение потоковой архитектуры онлайн-скоринга обеспечивает требуемую оперативность и масштабируемость, а использование метрик, чувствительных к дисбалансу, позволяет сбалансировать чувствительность и специфичность.
Практическая значимость выражается в сокращении времени выявления и снижении медианных потерь за счет более ранней эскалации инцидентов. Ограничения связаны с переносимостью результатов с открытых наборов на корпоративные данные, дрейфом распределений и необходимостью интерпретируемости решений; эти риски нивелируются регулярным переобучением, мониторингом дрейфа, настройкой порогов по фазам бюджетного и продуктового циклов и интеграцией с каналами корпоративного комплаенса.
В дальнейшем целесообразно расширить наборы данных реальными корпоративными выборками, валидировать графовые и гибридные архитектуры и формализовать методики объяснимости для управленческих решений.
