
Постановка научной проблемы
На сегодняшний день всё больше возрастает роль знаний, информации и информационных технологий в сферах образования. Поскольку информация является основой управления в любых областях и в полной мере определяет внешние и внутренние взаимодействия любого предприятия, вопрос ее систематизации становится ключевым. Тенденции модернизации и развития системы профессионального образования, необходимость повышения эффективности управления учебным процессом в вузах, а также непрерывно меняющиеся требования рынка труда предъявляют качественно новые требования организации, содержанию и совершенствованию технологий обучения. В связи с этим возникает потребностью анализа того, какие именно знания, умения, навыки, а также их сочетания необходимы студенту чтобы в будущем быть востребованным специалистом на рынке труда после окончания обучения.
На сегодняшний день большинство работодателей, особенно в сфере IT-технологий, выполняют поиск кадров в сети Интернет, размещая свои вакансии на сайтах-агрегаторах, таких как «indeed.com», «jooble.org», «Job.ru», «jobsinnetwork.com» и другие. Только на «HeadHunter.ru» зарегистрировано около 1215 тыс. проверенных компаний и представлено более 500 тыс. актуальных вакансий [1]. Поэтому источником данных для анализа был выбран вышеуказанный сайт «HH.ru». Выбор ресурса так же обусловлен наличием у данного ресурса открытого банка данных и API.
Для построения модели в работе применяются методы интеллектуального анализа данных (Data Mining), цель которого состоит в обнаружении новых закономерностей и зависимостей в исходной информации.
Решение задач ИАД – комплексный процесс, в котором выделяют следующие типовые этапы [2]:
- Анализ предметной области, формулировка целей и задач исследования.
- Извлечение и предварительная обработка данных
- Содержательный анализ данных методами Data Mining (установление общих закономерностей или решение более конкретных, частных задач).
- Интерпретация полученных результатов с помощью их представления в удобном формате и использование результатов.
Извлечение и предварительная подготовка данных
В качестве набора данных были использованы тексты вакансий в открытом доступе, опубликованные на агрегаторе «HH.ru». Выбор ресурса обусловлен как его масштабностью в России, так и наличием открытого API [3].
HeadHunter – один из самых крупных сайтов по поиску сотрудников в мире (5 место в мире в категории «Jobs And Career» по данным рейтинга Similarweb) [4]. Данные включают в себя информацию об актуальных вакансиях в IT-сфере по городу Москва. Размер выборки – 19500 записей, 17040 из которых уникальны.
Данные были получены с сайта компании путем веб-скрейпинга с использованием библиотек я.п. Python (requests, json, BeautifulSoup). Извлеченные таким путем данные требуют предварительной обработки.
Предварительная обработка слабоструктурированных данных, к которым можно отнести описание вакансий, очень объемный этап работы, который включает в себя: исключение вакансий с текстовые данных которых использовали не русский язык; фильтрацию (удаление спецсимволов, сокращений, изменение регистра); леммитизацию; удаление стоп-слов; морфологический анализ; токенизацию; выявление униграмм; сокращение. На этапе предварительной обработки использовались библиотеки python pymorphy2, pandas, nltk.
На обработанных был сформирован список навыков, содержащий 22000 позиций, что очевидно слишком много для проведения кластеризации. Анализ публикаций показывает, что большинство эффективных алгоритмов кластеризации ориентированы на небольшую размерность вектора, поэтому признаковое пространство требует сокращения. Далее была создана взвешенная матрица терм-документов с использованием статистической меры для оценки важности TF-IDF. Термы с низким весом исключаем из вектора признаков. Минимальное число вакансий, в которых должен был содержаться навык, для общего индекса равняется 100.
Результатом выполненных этапов является сокращение признакового пространства до 1200 наименований. На рисунке 1 представлен фрагмент диаграммы, показывающей частоту использования признаков в вакансиях.
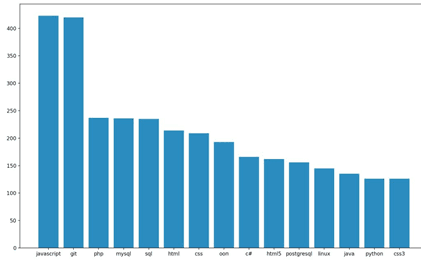
Рис. 1. Фрагмент диаграммы частоты упоминания навыков
Размерность результирующей матрицы терм-документов составила – 17040 на 1200 (размерность вектора – 17040, по числу вакансий, в качестве признака использовалось наличие или отсутствие навыка в вакансии).
Содержательный анализ данных методами Data Mining (кластеризация)
Выделение кластеров, заранее неизвестных групп сходных, связанных признаков, было проведено с использованием методов кластерного анализа. Данный подход позволит выявить знания, умения, навыки, которыми в соответствии с текущим запросом работодателей должен обладать соискатель какой-либо области ИТ, выявить их взаимосвязи и релевантность.
Существует множество алгоритмов кластерного анализа данных. Проведем тестирование предварительно обработанных данных, используя самые распространенные алгоритмы кластеризации: алгоритм k-средних, иерархическую кластеризацию методом Уорда и алгоритм Affinity Propagation, далее выберем самую интерпретируемую модель, наиболее полно описывающую выбранную предметную область.
Используем алгоритмом кластеризации k-средних [5]. Для выявления оптимального числа кластеров, проведем несколько итераций алгоритма с числом кластеров от 3 до 15 и в каждой вычислим метрики Elbow method и Silhouette score [6]. Результаты работы алгоритма представлены на рисунке 1.
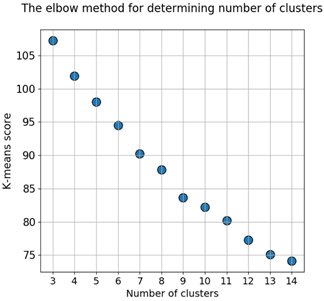
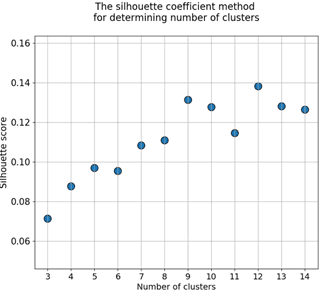
Рис. 2. Графики зависимости значений метрик от числа кластеров
По результатам вычисления метрик видно, что возможное оптимальное число кластеров 5, 7, 9 и 12.
Для уточнения результатов воспользуемся иерархической кластеризацией по методу Уорда [8]. Результаты визуализированы дендрограммой на рисунке 3.
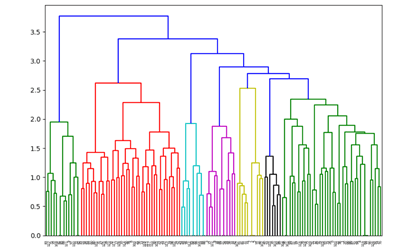
Рис. 3. Общий вид дендрограммы
Иерархическая кластеризации показала, что признаки, используемые в задачах одного вида, действительно являются связанными. Полученный результат кластеризации (6 кластеров) некоторые из которых уже можно интерпретировать. Кластер 1 содержит такие навыки как [‘1c зарплата и управление персоналом’, ‘1c: бухгалтерия’, ‘1c erp’ и др.] из чего можно сделать вывод что в данный кластер попали умения необходимые специалисту 1С. Кластер 2 включает в себя ['JavaScript', 'CSS', 'Git', PHP, '1c-Битрикс', 'HTML', 'Node.js'], по которым можно сделать предположение, что в данный кластер попали навыки необходимые в web-разработке. В кластр 3 попали признаки ['.net framework', 'asp.net', 'c#', 'ooп'] соответствующие профилю .NET-разработчика.
В результате работы алгоритма Аffinity Рropagation были сформированы 13 кластеров, некоторые из которых содержали в себе менее 100 элементов
Учитывая все особенности поставленной задачи и выбранных данных, выбор был остановлен на алгоритме иерархической кластеризации методом Уорда. Основным плюсом данного алгоритма применительно к нашей задаче – это легкость визуализации и чтении результатов.
Результаты
В результате работы была создана и протестирована модель востребованного ИТ-специалиста на основе нечеткой кластеризации.
Были извлечены сведения о навыках IT-специалистов, указываемых в вакансиях. Извлеченные данные были предварительно обротаны. Рассмотрены различные методы предварительно обработки данных, и представления слабоструктурированной информации в виде, пригодном для дальнейшего анализа. Проведен содержательный анализ различными методами кластеризации, а именно методом K-means, Ward agglomerative hierarchical clustering и Аffinity Рropagation, и выбран наиболее точно работающий на нашей модели метод.
Так же в процессе создания и тестирования модели были извлечен набор навыков, характеризующих специалистов различных областей ИТ. Самыми востребованными и часто упоминаемыми навыками стали «Javascript» и «Git». Сделан вывод о связанности признаков одного направления.
Полученную модель реализована на языке программирования Python и ее планируется интегрировать в систему интеллектуальной оптимизации индивидуальных образовательных траекторий.
