
Введение
Одним из простейших способов построения синтаксического анализа по LL(1)-грамматике является метод рекурсивного спуска. Этот метод реализуется на любом императивном языке программирования, в котором есть возможность рекурсивного вызова функций или процедур. Недостатком метода является смешение алгоритма и правил грамматики в коде получаемого анализатора, что ведет к снижению читаемости и мобильности исходного кода и, как следствие, к ошибкам при разработке. Предлагаемый способ позволит формализовать процесс программирования синтаксического анализатора благодаря использованию абстракции МП-автомата.
Таким образом, МП-автомат используется как промежуточное звено перед реализацией грамматики на алгоритмическом языке. МП-автомат в этом плане абстрактнее конкретной программы, поскольку подразумевает несколько возможностей реализации в программном коде.
Использование приведенного в статье метода позволит получать доказуемо правильный код программы.
Объекты и методы исследования
Различные методы синтаксического анализа с использованием формальных грамматик широко используются для разработки компиляторов [1, с. 35]. Кроме того, часть этих методов можно применять для проверки корректности:
- вводимой информации,
- передаваемых данных,
- интерфейсных программных взаимодействий.
Формализация правил проверок в форме контекстно-свободной грамматики LL(1) [2, с. 96] позволяет реализовать синтаксический анализатор (распознаватель, парсер) на любом алгоритмическом языке высокого уровня, используя метод рекурсивного спуска [1, с. 120].
Кроме того, известно соответствие LL(1)-грамматики и МП-автомата [2, с. 79]. Совмещение обоих подходов, как будет показано ниже, позволяет формализовать, а при необходимости автоматизировать разработку программ, реализующих метод рекурсивного спуска.
Удобство LL(1)-грамматик выражено в том, что для выбора применяемого правила достаточно иметь информацию об одном входном символе. Конечно, это накладывает дополнительные требования к формированию правил грамматики [1, с. 115], но в случаях простых синтаксических разборов ограничения несущественны.
Для примера составим правила LL(1)-грамматики для упрощенного варианта SQL-запроса «select»:
«select столбец1, столбец2, … from таблица1, таблица2, …»
Поскольку темой статьи является синтаксический анализ, то исключим из рассмотрения лексический анализ (сканер) входной строки, и для этого будем считать, что каждый входной символ грамматики является лексемой. Таким образом, используем следующие замены входной строки:
- вместо токена «select» будем использовать символ «s»,
- вместо токена «from» будем использовать символ «f»,
- вместо названий полей символы «a» или «b»,
- «$» будет обозначать конец строки.
С учетом указанных замен распознаваемая в примерах строка будет иметь форму: «s a,b,a,a f a,a,a,b,b,b,a$».
LL(1)-грамматика, по которой будем строить синтаксический анализатор, получается следующей:
- S → sXfX
- X → AY
- Y → ,AY
- Y → ɛ
- A → a
- A → b
В приведенных выше правилах заглавными буквами указаны нетерминальные символы, маленькими буквами – терминальные, то есть составляющие входную строку. «Ɛ» – пустой символ, и правило 4, соответственно, аннулирующее.
Выстраиваемый далее МП-автомат, эквивалентный LL(1)-грамматике, состоит из следующих элементов:
- множество состояний,
- множество входных символов на входной ленте,
- магазинные (стековые) символы,
- функция переходов,
- начальное состояние,
- символ конца магазина,
- множество допускающих состояний.
Входные символы: символы из входной строки, то есть терминальные, с точки зрения МП-автомата записаны на входную ленту.
Магазинные символы: все нетерминальные символы грамматики и терминальные символы, которые могут находиться не на первом месте в правой части правил грамматики.
Состояния:
- рабочее состояние,
- состояние «синтаксическая ошибка»,
- состояние «успешное завершение».
Переход в состояние «синтаксическая ошибка» производится, если входная цепочка символов не соответствует правилам грамматики, по которым построен МП-автомат.
Возможные в рабочем состоянии действия со стеком и с входной лентой приведены в таблице.
Таблица
Действия МП-автомата в рабочем состоянии
|
Действие |
Обозначение |
|
Вытолкнуть из стека символ | 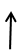 |
|
Заменить символ в стеке цепочкой символов | 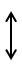 |
|
Сдвиг вправо по входной ленте | 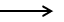 |
|
Не двигать входную ленту (стоять на месте) | 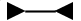 |
|
Переход в состояние «синтаксическая ошибка» |
- |
|
Переход в состояние «успешное завершение» |
+ |
В состояниях «синтаксическая ошибка» и «успешное завершение» автомат не выполняет никаких действий вне зависимости от входной ленты и состояния стека. Эти состояния сигнализируют о результате синтаксического анализа. Результаты работы МП-автомата выражены именно состояниями, а не выходными сигналами, чтобы не нарушать классическую модель МП-автомата, не подразумевающую выходных сигналов.
Для наглядности за счет визуализации и удобства выполнения дальнейших шагов по построению метода рекурсивного спуска при относительно небольшом количестве магазинных и терминальных символов удобно использовать табличную форму записи функции переходов.
Пример функции переходов, заданной в табличной форме, приведен на рис. 1.
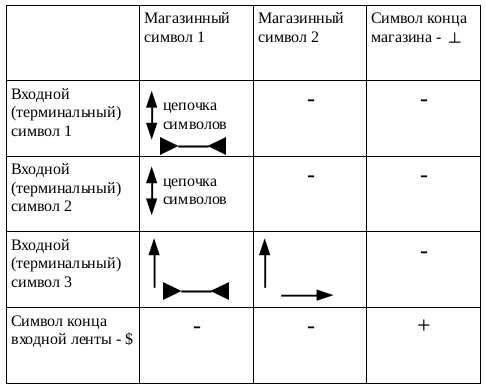
Рис. 1. Таблица переходов
По таблице переходов можно проследить сразу все составляющие МП-автомата: магазинные и входные символы, действия с магазином и переходы между состояниями.
Построение МП-автомата по LL(1)-грамматике в целом соответствует устоявшейся практике [3, c. 44], но приведем это построение в разрезе построения таблицы переходов для удобства дальнейшей разработки программы, реализующей метод рекурсивного спуска.
Для построения МП-автомата выделим четыре вида правил LL(1)-грамматик:
- Правила LL(1)-грамматики, в которых левая часть начинается с терминального символа;
- Правила LL(1)-грамматики, в которых левая часть начинается с нетерминального символа;
- Правила LL(1)-грамматики, в которых левая часть содержит один терминальный символ;
- Аннулирующее правило LL(1)-грамматики.
Правила первого вида имеют форму:
A → xB
В формуле использованы следующие обозначения:
A – одиночный нетерминальный символ,
x – одиночный терминальный символ,
B – цепочка любых символов.
Этой формуле будет соответствовать ячейка таблицы переходов МП-автомата, изображенная на рис. 2.
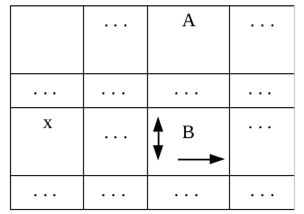
Рис. 2
Правила второго вида имеют форму:
A → СB
В формуле использованы следующие обозначения:
A – одиночный нетерминальный символ,
С – одиночный нетерминальный символ,
B – цепочка любых символов.
Этой формуле будет соответствовать ячейка таблицы переходов МП-автомата, изображенная на рис. 3.
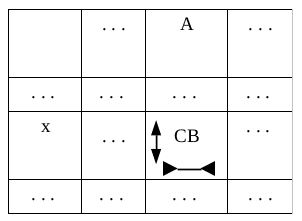
Рис. 3
На рис. 3 x принадлежит множеству первых символов сверток, полученных из С.
Правила третьего вида имеют форму:
A → x
В формуле использованы следующие обозначения:
A – одиночный нетерминальный символ,
x – одиночный терминальный символ.
Этой формуле будет соответствовать ячейка таблицы переходов МП-автомата, изображенная на рис. 4.
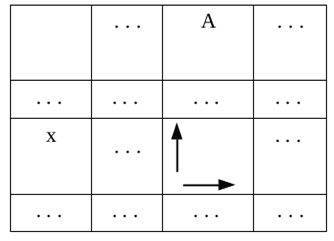
Рис. 4
Правила четвертого вида (аннулирующие) имеют форму:
A → ɛ
В формуле использованы следующие обозначения:
A – одиночный нетерминальный символ,
ɛ – пустой символ.
Этой формуле будет соответствовать ячейка таблицы переходов МП-автомата, изображенная на рис. 5.
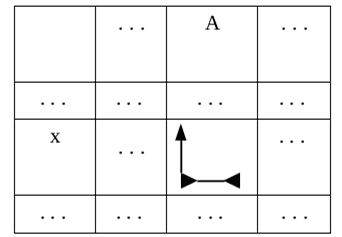
Рис. 5
При этом x принадлежит множеству первых символов следующих за A в cвертках рассматриваемой грамматики.
Кроме действий (ячеек таблицы переходов), непосредственно составленных в соответствии с правилами грамматики, необходимо МА-автомат дополнить следующими действиями.
Для ячеек таблицы переходов, у которых в столбцах и в строках совпадают символы, необходимо указать действия согласно рис. 6.
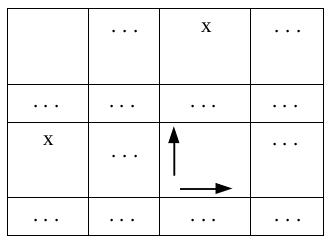
Рис. 6
Для ячейки таблицы переходов, соответствующей концу входной ленты и символу конца магазина, указывается действие – переход в состояние «успешное завершение» согласно рис. 7.
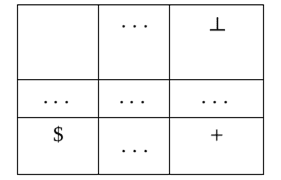
Рис. 7
Для остальных незаполненных ячеек указывается переход в состояние «синтаксическая ошибка».
Для начала синтаксического разбора в магазин должен быть загружен начальный нетерминальный символ, МП-автомат находится в состоянии «рабочее состояние».
Для примера с грамматикой SQL-запроса «select» МП-автомат будет выглядеть как показано на рис. 8.
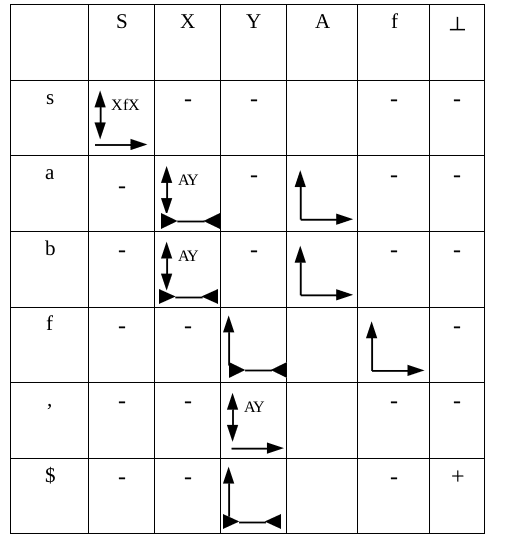
Рис. 8
При наличии подобным образом построенного МП-автомата разработать программу на алгоритмическом языке, реализующую метод рекурсивного спуска, можно следуя четкому набору правил, соответствующих каждому виду из рассмотренных выше ячеек таблицы переходов МП-автомата.
Основные правила построения программы, реализующей метод рекурсивного спуска:
- каждому магазинному символу должна соответствовать функция в языке программирования;
- очередной входной символ должен быть доступен глобально для всех функций;
- сдвиг по входной ленте реализуется через вызов функции получения следующего символа или вызов лексического анализатора для получения очередной лексемы/токена;
- повторяя принцип синтаксического разбора с помощью МП-автомата, в начале программы необходимо вызвать функцию, реализующую начальный нетерминальный символ, а по завершению этой функции (что соответствует пустому магазину) проверить достижение конца входной строки;
- выталкиванию символа из стека соответствует завершение функции, а помещению символа в стек – вызов функции, что сочетается с принципом помещения в стек записей активации функций в ряде языков программирования, например, в Си.
Функции, определяющие терминальные магазинные символы, должны, согласно таблице переходов, проверить соответствие текущего входного символа ожидаемому. И инициировать получение следующего входного символа. Если пришел недопустимый символ, то выполнение синтаксического анализа должно прерваться.
В примере с SQL-запросом одним из магазинных символов является «Y». Код функции, реализующей этот магазинный нетерминальный символ, определяется столбцом «Y» таблицы переходов на рис. 8.
Тело соответствующей функции для Си-подобных языков должно выглядеть следующим образом:
switch( x ) {
case 'f': yylex(); break;
default: stateerr(); break;
}
Здесь yylex() – функция получения следующего входного символа, с точки зрения МП-автомата – сдвиг по входной ленте. Выталкивание символа из стека – видно, что никакая больше функция не вызывается, значит выполнение функции завершится. Если входной символ отличен от «f», выполнятся действия по конструкции «default» – выполнится функция, соответствующая переходу в состояние «синтаксическая ошибка».
Функции, определяющие нетерминальные магазинные символы, строятся по следующим правилам:
- в зависимости от входного символа выполняются действия согласно соответствующим ячейкам таблицы переходов МП-автомата, в том числе: вызов функций (помещение в стек), переход к следующему входному символу (сдвиг по входной ленте), завершение функции;
- при недопустимых символах синтаксический анализ должен прерываться.
В примере с SQL-запросом в стек помещается терминальный символ «f». Код функции определяется столбцом «f» таблицы переходов на рис. 8.
Тело соответствующей функции для Си-подобных языков должно выглядеть следующим образом:
switch( x ) {
case 'f': break;
case '$': break;
case ',': yylex(); A(); Y(); break;
default: stateerr(); break;
}
В этом коде, как и в таблице переходов МП-автомата, для входных символов «f» и «$» (конец строки/ленты) лента стоит на месте (не вызывается функция получения очередного входного символа «yylex()»), выталкивается нетерминальный символ «Y» из стека (функция завершается). А при входном символе «,» (запятая) производится сдвиг по ленте (вызов функции получения очередного входного символа), текущий символ магазина «Y» заменяется на «А» и «Y» (вызов функций «А()», «Y()» и последующее завершение текущей функции «Y()»). Если входной символ отличен от {«f»,«$»,','}, выполнятся действия по конструкции «default» – выполнится функция, соответствующая переходу в состояние «синтаксическая ошибка».
Результаты и их обсуждение
Программа для разбора строки "sa,b,a,afa,a,a,b,b,b,a$" реализована на JavaScript и выполняется в современных веб-браузерах. Особенностями программы являются:
- входная строка записана в виде массива символов;
- неуспешное завершение синтаксического анализа отрабатывается функцией stateerr(), генерирующей исключительную ситуацию (для прекращения рекурсивного вызова функций и выхода из всех рекурсий), обрабатываемую конструкцией «try-catch»;
- информация об результатах анализа («+» или «-») отображается на веб-странице.
Полная версия программы будет выглядеть следующим образом.
<body>
<script>
var input = "sa,b,a,afa,a,a,b,b,b,a$";
var pos = 0;
var x = '';
yylex = () =>
{
x = input[pos];
pos++;
}
stateok = () => {
document.write('+');
}
stateerr = () => {
throw "-";
}
main = () => {
yylex();
S();
switch( x ) {
case '$': stateok(); break;
default: stateerr(); break;
}
}
S = () => {
switch( x ) {
case 's': yylex(); X(); f(); X(); break;
default: stateerr(); break;
}
}
X = () => {
switch( x ) {
case 'a': A(); Y(); break;
case 'b': A(); Y(); break;
default: stateerr(); break;
}
}
A = () => {
switch( x ) {
case 'a': yylex(); break;
case 'b': yylex(); break;
default: stateerr(); break;
}
}
Y = () => {
switch( x ) {
case 'f': break;
case '$': break;
case ',': yylex(); A(); Y(); break;
default: stateerr(); break;
}
}
f = () => {
switch( x ) {
case 'f': yylex(); break;
default: stateerr(); break;
}
}
try {
main();
}
catch (e)
{
document.write('-');
}
</script>
Заключение
Приведенный метод позволяет за считанные минуты составить доказуемо правильную программу. Естественно при этом должна быть предварительно составлена формальная грамматика LL(1).
В рассмотренном примере вместо лексем (токенов) используются непосредственно входные символы. Но метод без какой бы то ни было модификации позволяет полученному синтаксическому анализатору работать в паре с лексическим анализатором. Потребуется только заменить символы, заданные константами в конструкции «case», на токены/лексемы (например, использовав макроопределения с помощью #define) и переопределить функцию получения очередного символа «yylex()», название которой выбрано неслучайно (именно так называет функцию генератор лексического анализатора «lex»).
Благодарности
Выражаю благодарность учителю и руководителю Соловьеву А.Е., который говорит, что переход от неформального к формальному неформален; студентам ПНИПУ, в свое время согласившимся участвовать в безуспешном (с точки зрения студентов) и успешном (с точки зрения автора) эксперименте по построению синтаксического анализатора специально без использования рассмотренного (да и вообще, какого бы то ни было) метода; жене, если в статье нет описок.
