
Актуальность исследования
В условиях поздней стадии разработки месторождений наблюдается устойчивый рост обводнённости добываемой продукции, что приводит к снижению нефтеотдачи и экономической эффективности операций. Традиционные методы прогнозирования, такие как гидродинамическое моделирование или эмпирические формулы, всё чаще сталкиваются с ограничениями: они требуют больших объёмов исходных данных, высоких вычислительных ресурсов и часто не справляются с учётом геолого-технологической неоднородности.
Современные исследования показывают, что подходы на основе машинного обучения обладают масштабируемостью, позволяют гибко интегрировать как статические (геолого-технологические), так и динамические (производственные, временные ряды) параметры, а также могут моделировать сложные нелинейные зависимости, недоступные для традиционных методов. Например, создание гибридных моделей (PIML), которые объединяют физическое моделирование и алгоритмы машинного обучения, позволяет повысить точность прогнозов и адаптивность в условиях меняющихся величин, таких как обводнённость и дебит.
Таким образом, исследование применения ML-алгоритмов для прогнозирования обводнённости скважин отвечает не только научному, но и практическому запросу нефтегазовой отрасли на повышение эффективности добычи, снижения затрат и риска промысловых операций.
Цель исследования
Цель данного исследования заключается в разработке теоретической методологической базы применения алгоритмов машинного обучения для прогнозирования обводнённости скважин на поздней стадии разработки нефтяных месторождений.
Материалы и методы исследования
Исследование основано на анализе научных публикаций и инженерных отчётов, доступных в открытых источниках. Материалы включают данные по эксплуатационным характеристикам скважин, типовые кривые роста обводнённости, описания геологических условий и методы их интерпретации. Методологически использован обзорный подход, с классификацией алгоритмов машинного обучения (линейные регрессии, деревья решений, ансамбли, нейронные сети), анализом их применимости к задачам прогнозирования, а также синтезом рекомендаций по построению архитектуры моделей. Были рассмотрены подходы к валидации моделей, включающие кросс-валидацию, методы скользящего окна, использование метрик RMSE, MAE, R², а также подходы Explainable AI (SHAP, LIME).
Результаты исследования
Обводнённость скважин – это коэффициент, отражающий удельную долю воды в добываемой нефтесодержащей жидкости [4].
В таблице 1 представлены основные факторы, влияющие на рост обводнённости скважин на поздней стадии разработки месторождений.
Таблица 1
Факторы, влияющие на рост обводнённости
Категория фактора | Фактор | Влияние на обводнённость |
Геологические | Неровномерная проницаемость пласта | Прорыв воды по наиболее проницаемым зонам |
Наличие высокопроницаемых пропластков и линз | Формирование каналов для быстрого продвижения воды к забою | |
Трещиноватость пород | Ускоренный прорыв воды по естественным трещинам | |
Наклон пласта и гравитационное перераспределение | Переток воды к нижним частям залежи, обводнение нижнего горизонта | |
Технологические | Интенсивное закачивание воды (ППД, заводнение) | Повышение пластового давления и преждевременный контакт воды с продуктивной зоной |
Неоптимальное размещение нагнетательных скважин | Локальные прорывы воды при отсутствии фронтального вытеснения | |
Повышенные скорости отбора | Изменение градиента давления → захлёст воды в добывающие скважины | |
Отсутствие изоляции водоносных пропластков | Прямая добыча воды без возможности управления её притоком | |
Эксплуатационные | Продолжительная эксплуатация с водонагнетанием | Постепенное вытеснение нефти и замещение её водой в призабойной зоне |
Износ цементного кольца и обсадных колонн | Вертикальный прорыв воды из подстилающих горизонтов | |
Нарушения в режиме работы скважины | Флуктуации давления, приводящие к изменению направления движения флюидов | |
Природно-физические | Высокая вязкость нефти | Снижение эффективности вытеснения, повышенная вероятность обводнения |
Низкая нефтенасыщенность | Быстрое замещение нефти водой при малом запасе | |
Высокая минерализация воды | Влияние на фильтрационные свойства пород, изменение профиля вытеснения |
Обводнённость определяется распределением флюидов в залежи, где вода, нефть и газ располагаются в определённой последовательности под действием гравитации и капиллярных сил. Типичная модель залежи представлена на рисунке 1 [5].
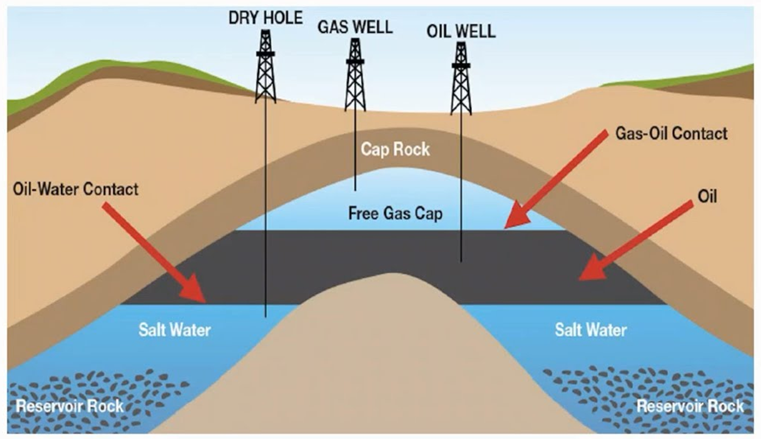
Рис. 1. Структурная модель залежи нефти, газа и воды в пласте-коллекторе
На протяжении жизненного цикла разработки нефтяного месторождения процесс обводнённости скважин проходит несколько стадий, каждая из которых характеризуется различными геофизическими, технологическими и гидродинамическими проявлениями [1, с. 437]. Условно весь цикл можно разделить на три основные стадии: начальную, промежуточную и позднюю.
Начальная стадия характеризуется преобладанием нефти в добываемой продукции, минимальным содержанием воды (обычно менее 10–15%) и стабильными дебитами. На этой стадии система фильтрации функционирует в квазистационарном режиме, движение флюидов в пластах подчиняется законам ламинарного течения, фронт нагнетаемой воды ещё далёк от забоя добывающей скважины. Проблемы, связанные с обводнением, в этот период, как правило, не носят выраженного характера и поддаются локальному контролю.
Промежуточная стадия наступает по мере приближения водонагнетательного фронта к добывающим скважинам. Доля воды в продукции начинает устойчиво расти, наблюдаются нестабильные колебания дебита нефти, особенно в скважинах, расположенных в высокопроницаемых или трещиноватых зонах. Именно на этом этапе важно применять меры по регулированию фильтрационных потоков и выборочной изоляции водоносных зон. Водонефтяной фактор (WOR – water-oil ratio) возрастает, но ещё не достигает критических значений.
Поздняя стадия разработки сопровождается устойчивым ростом обводнённости, часто превышающим 80–90 %, и падением эффективности традиционных методов воздействия на пласт. На этой стадии в значительной части добывающих скважин основным извлекаемым флюидом становится вода, в то время как дебит нефти падает до минимальных значений. Фильтрационные потоки становятся крайне неравномерными, наблюдается прорыв воды по отдельным каналам или высокопроницаемым пропласткам, вызывая эффект «конуса воды» или «газлифтного выброса» в вертикальной колонне скважины.
Характерными признаками высокой обводнённости на поздней стадии разработки являются:
- Резкий рост водонефтяного фактора (WOR) – экспоненциальное увеличение отношения воды к нефти.
- Существенное снижение дебита нефти при росте общего дебита жидкости
- Увеличение затрат на сепарацию и переработку пластовой воды.
- Устойчивый тренд на замещение нефти водой в продуктивном интервале.
- Невозможность экономически обоснованной эксплуатации скважины без дополнительных мероприятий (изоляция, водоотвод и пр.).
Исследования показывают, что после достижения обводнённости в 95–98% даже незначительное увеличение водоотдачи не приводит к существенному росту нефтеотдачи, и эксплуатация скважины становится нерентабельной. Это обусловлено тем, что подача энергии в пласт преимущественно расходуется на перемещение воды, а нефть остаётся в труднодоступных зонах [2, с. 73].
В таблице 2 представлены ключевые алгоритмы машинного обучения, применяемые в задачах прогнозирования обводнённости нефтяных скважин на поздней стадии разработки месторождений.
Таблица 2
Сравнительный обзор алгоритмов машинного обучения для прогнозирования обводнённости скважин
Алгоритм | Задача | Преимущества | Недостатки |
MLR/PLR | Регрессия | Простота, интерпретируемость | Низкая точность при нелинейности |
SVR | Регрессия | Устойчивость, эффективен на малых наборах | Чувствителен к выбору ядра, параметров |
Decision Tree | Классификация/регрессия | Простой, быстрый, интерпретируемый | Склонен к переобучению |
Random Forest (RF) | Регрессия | Высокая точность, устойчивость к шуму | Требует настройки гиперпараметров |
XGBoost | Регрессия | Лучшая производительность, R² ≈ 0.96 для добычи и обводнённости | Сложнее интерпретации, чувствителен к выбору параметров |
MLP (нейросеть) | Регрессия/классификация | Улавливает нелинейности, хорошие результаты R² ≈ 0.97-0.98 | Требует большого объёма данных, долго обучается |
RNN (LSTM, GRU) | Временные ряды | Лучшая модель для оценки трендов обводнённости на поздних стадиях | Дорогие вычисления, сложно настраивать |
VAR/авторегрессия | Временные ряды | Учет когерентности соседних процессов, подходит для sweet / salty wells | Ограничен линейностью |
Современная классификация ML‑методов для прогнозирования обводнённости предполагает использование ансамблей и нейросетевых моделей, при том, что регрессия отвечает за интерпретируемость, а временные модели – за динамику. Отдельные подходы для распознавания диапазонов обводнённости и гибридные структуры усиливают надёжность прогнозов.
Сравнение фактической и прогнозируемой обводнённости скважины с использованием алгоритма машинного обучения (пример SVR) представлено на рисунке 2.
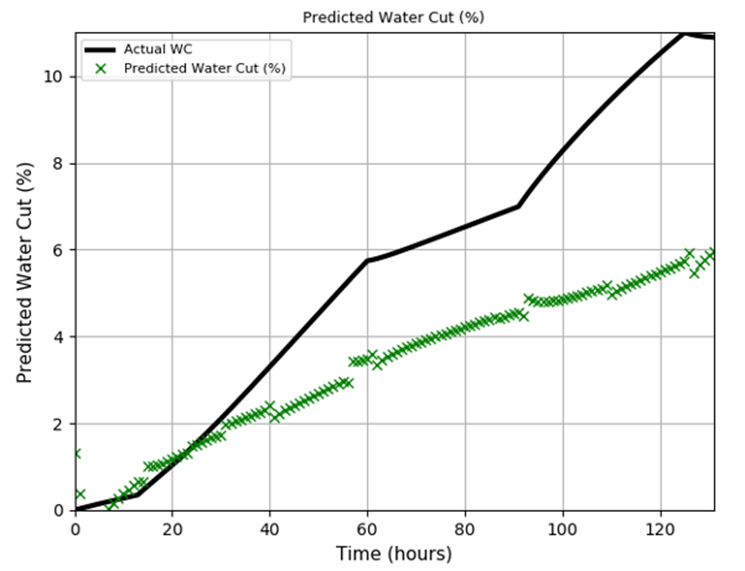
Рис. 2. Сравнение фактической и прогнозируемой обводнённости скважины с использованием алгоритма машинного обучения (пример SVR)
Эффективность моделей зависит от качества предварительной обработки данных – нормализации, устранения выбросов, заполнения пропусков и создания новых производных признаков.
Модели типа Random Forest и XGBoost показывают высокую точность при работе с коррелированными данными и обеспечивают интерпретируемость через анализ важности признаков. В то же время нейросетевые архитектуры, особенно LSTM и CNN-LSTM, превосходят по точности при прогнозировании во времени, особенно при наличии сложных, нелинейных зависимостей и скачкообразного роста обводнённости. Для улучшения качества временных моделей успешно применяются методы декомпозиции сигналов (например, CEEMDAN), которые позволяют лучше выделить скрытые тренды.
Валидация осуществляется с помощью кросс-валидации и скользящих окон, а метрики оценки (RMSE, MAE, R²) позволяют объективно сравнивать модели. В ряде исследований гибридные подходы, сочетающие декомпозицию и глубокое обучение, обеспечили лучшие результаты по точности прогнозирования (до R² = 0,97).
Применение алгоритмов машинного обучения в задачах прогнозирования обводнённости скважин открывает новые возможности, однако сопровождается рядом ограничений и рисков, которые необходимо учитывать при построении и интерпретации моделей.
Одной из ключевых проблем является ограниченность и некачественность исходных данных. Исторические данные по добыче часто имеют пропуски, шум, неточные замеры, а также различаются по частоте измерений и полноте набора признаков. Особенно это актуально для старых месторождений, где эксплуатационные журналы вели вручную, а систематическая цифровизация началась сравнительно недавно. Это усложняет подготовку обучающего датасета, снижает точность прогнозов и увеличивает вероятность переобучения модели на шуме.
Переобучение – ещё один распространённый риск. При использовании моделей с высокой степенью свободы, таких как нейросети или градиентные бустинговые алгоритмы, существует вероятность, что модель будет точно запоминать обучающие данные, но терять способность обобщать. Это особенно опасно в условиях резких колебаний обводнённости или появления неучтённых технологических изменений (например, смена режима закачки воды или изоляция обводнённого интервала).
Отдельной проблемой выступает интерпретируемость моделей. В нефтегазовой отрасли важно, чтобы результаты прогноза были объяснимы инженерам и принимались в расчёт при принятии решений. Однако многие эффективные алгоритмы (например, LSTM, XGBoost) работают как «чёрные ящики», что ограничивает их использование в критически важных объектах без дополнительного слоя интерпретации, такого как SHAP-анализ или LIME.
Существенным ограничением остаётся нестабильность моделей при выходе за пределы обучающей выборки. Даже при высокой точности на тестовых данных модель может давать ошибочные прогнозы при изменении внешних условий: изменении геологии, внедрении новых технологий разработки, изменении структуры флюида. Это требует регулярной переобучаемости моделей, настройки контроля дрифта данных и мониторинга актуальности признаков.
Нельзя не учитывать и высокую вычислительную сложность. Глубокие нейронные сети и ансамбли требуют больших вычислительных ресурсов, особенно при работе с временными рядами в реальном времени. Это ограничивает возможности применения ML-моделей в условиях обособленных кустовых площадок с ограниченными вычислительными мощностями или отсутствием связи с централизованной ИТ-инфраструктурой [3, с. 115].
Также существует риск ложной корреляции. ML-модели склонны находить статистические зависимости, не имеющие физического смысла, особенно в случае малого объёма данных. Это может привести к созданию внешне точных, но нефизичных моделей, что недопустимо в промышленной эксплуатации.
Для эффективного применения методов машинного обучения при прогнозировании обводнённости скважин необходима чёткая методологическая основа. На первом этапе осуществляется сбор и формирование признаков: геологических (проницаемость, пористость), технологических (дебиты, давление), а также временных рядов обводнённости. Важно дополнительно использовать производные параметры – скользящие средние, темпы изменения, расстояние до нагнетательных скважин.
Предобработка данных включает устранение выбросов, нормализацию, заполнение пропусков и при необходимости – декомпозицию временных сигналов (например, методом CEEMDAN), что особенно актуально для моделей, основанных на нейросетевых архитектурах.
Далее следует построение и обучение моделей. Используются как базовые алгоритмы (линейная регрессия, SVR), так и продвинутые – Random Forest, XGBoost, LSTM, CNN-LSTM. Перспективным направлением остаются гибридные подходы, объединяющие временные и пространственные зависимости.
Оценка точности выполняется с помощью перекрёстной проверки (кросс-валидации), методов скользящего окна и метрик RMSE, R², MAE и др. Обязательным становится использование инструментов интерпретации (SHAP, LIME), позволяющих объяснить работу модели.
Для промыслового применения необходимо обеспечить адаптивность: регулярное обновление данных, контроль смещения признаков (data drift) и возможность интеграции с физико-математическими симуляторами (например, Eclipse или CMG) в рамках концепции гибридных моделей (Physics-Informed ML).
Выводы
Таким образом, алгоритмы машинного обучения обладают значительным потенциалом для повышения точности прогнозирования обводнённости скважин на поздней стадии разработки. Их ключевыми преимуществами являются способность к обучению на неоднородных данных, моделирование сложных нелинейных зависимостей, а также возможность интеграции с физическими моделями в рамках гибридного подхода.
Наиболее перспективными методами признаны ансамблевые алгоритмы и рекуррентные нейросети, особенно при использовании расширенных временных признаков и методов декомпозиции сигналов. Однако внедрение таких моделей требует учёта рисков – ограниченности данных, переобучения, сложности интерпретации и необходимости адаптации моделей к изменяющимся условиям разработки.
Предложенная методологическая рамка позволяет сформировать устойчивый научный фундамент для дальнейших прикладных и производственных решений в сфере цифровизации добычи.
